Reliable, resilient storage with GlusterFS
A need came up lately for some inexpensive resilient storage that was easily expandable, and that spanned multiple datacentres. Having recently been playing with GlusterFS and Swift in our OpenStack trial, I was quick to point out that these were strong use-cases for a GlusterFS architecture. We needed something right away, and something that also wasn’t terribly expensive, which Gluster caters to quite well. Typically we would purchase a SAN technology for this, but recently having some discussions on cost and business agility, we decided against that and opted to try a popular open source alternative that’s been gaining both momentum and adoption at the enterprise level.
I began researching the latest best-practise architecture for GlusterFS. It’s been about a year since I’ve given it a deep investigation, so I started re-reading their documentation. I was pleasantly surprised to see that quite a bit more work had been done on the documentation since I last checked-in with the project. They’ve recently moved a lot of documentation into github, and redesigned their website as well. I found some good information on their website here, but found the most useful information in github here.
Our storage needs for this project were very simple. We need resilient, highly available storage that can expand quickly, but don’t need a ton of IOPs. Databases and other intense I/O applications are out of scope of this project, so what we’re mostly looking for out of this architecture is basic file storage for things like:
- ISOs
- Config file backups
- Restored file location
- Static web files
- FTP/Dropbox/OwnCloud file storage
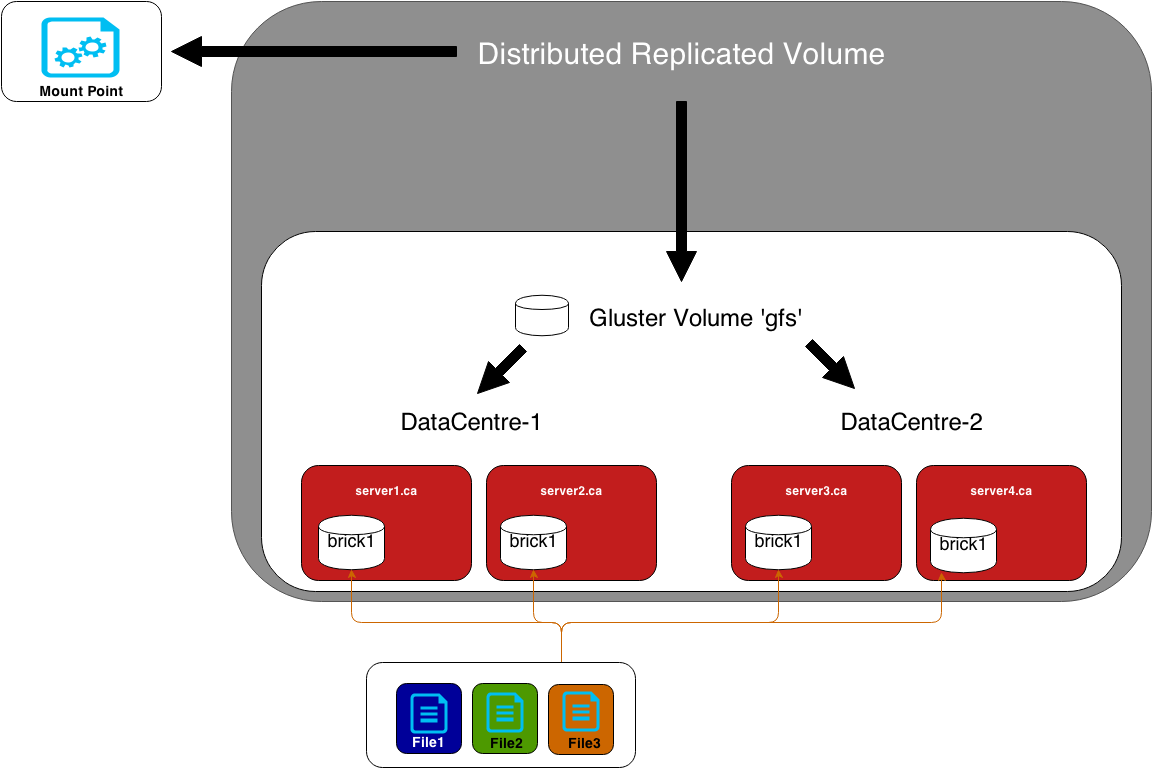
After perusing through Gluster.org‘s documentation, I came across the architecture that would best suit our needs. Distributed replicated volumes. We wanted two servers in each datacentre to have a local copy of this data, and also have two copies stored in another datacentre for resiliency. This way we can suffer a server loss, a server loss in each datacentre, or an entire datacentre loss and still have our data available. The documentation even gives you the command syntax to create this architecture; perfect! I wanted to change the architecture slightly, but that wasn’t a big deal. There’s enough detail in the documentation that I was able to understand how to do this.
- I racked 2 CentOS 6.5 servers in each datacentre (for a total of 4. I had four Dell R420s that were decomissioned from another project – commodity hardware)
- Installed gluster-server on them all via the glusterfs-repo
- Made sure their DNS was resolvable for both forward and reverse
- Chopped up their RAID10 1TB hard disk with LVM leaving approx 80GB for the OS, and the rest for /gfs/brick1
…and I was ready to run their provided command – slightly modified of course. Since I wanted the data to essentially be replicated across all 4 nodes, I changed the replica count from 2 to 4. This means if I ever need to expand, I’ll need to do it 4 nodes at a time. I then ran this command on one of the cluster members to create the gluster volume named ‘gfs’:
gluster volume create gfs replica 4 transport tcp server1:/gfs/brick1 server2:/gfs/brick1 server3:/gfs/brick1 server4:/gfs/brick1
For a visual reference, this is what this architecture looks like:
That’s it! I could now install the glusterfs and glusterfs-fuse client software on any node that needed to access this volume, and mount it with
mount -t glusterfs server1:/gfs /mnt
After succesfully mounting the volume, I did a few file writing tests with bash for loops, and dd, just to test the speed and see that any created files were replicating. I then did a few failover tests by shutting down an interface on a node, rebooting a node completely, and shutting down two nodes in a datacentre. Since I am using the native glusterfs client to connect to the volume, the failover and self-healing features are automatically handled unbeknownst to the user. After the 42 second timeout, services failed over nicely, and files were replicated across active hosts. When the downed nodes came back up and joined the volume again, the files they missed were automatically copied over. Perfect! And just like that – I was done.
I was surprised at how simple this was to architect and setup. When I need additional disk space, I’ll rack another 4 nodes into the architecture, and expand it by using the gluster volume add-brick command documented here.
In another article, I plan to do some tweaking to the 42 second TCP timeout – Gluster provides documentation on all the options and tuneables you can set. It’s also worth looking at using an IP-based load balancing technology. (Either an F5, or CTDB). This should increase the service availability even further. In yet another article, I would also like to explore the new geo-replication technology that spans WANs and the internet. For now, I have a 1TB highly available and resilient file storage volume to play with.