Automating Server Provisioning; the Transition to Private Hybrid Cloud
In every place I’ve worked, the server provisioning process was largely identical. There were of course subtle differences depending on vendor products, business processes, etc. but typically every customer’s server provisioning artifacts are made up of the same components. To provision a host, you’ll need IP information, DNS entry, VM container, a kickstart/jumpstart method, pre-provisioned storage/networks, and all of the various application level components on top of the OS (monitoring agents, backups, the application itself, etc.). These systems or processes usually had been in place for more than a few years, and would be considered the “Traditional IT” method of provisioning servers.
Since most of these components are a few to several years old, it’s accurate to say that not all of them were designed with true automation in mind. Some components had automation capability, but generally these existed in isolation and had manual kick-off processes or dependencies associated to them. In one particular shop, our home-grown asset management tool was completely manual. We could build an OS in an automated fashion, but had to wait for manual asset management tasks to be completed post-build before we could hand it over to a developer. In another shop, our IP address management tool didn’t have an API. We followed many manual steps to reserve and setup IP/DNS before we could kick off an automated OS build. In all of these server provisioning scenarios, a developer would be waiting anywhere from 4-10 hours (rush request) to 2 – 3.5 weeks before they could get their server. The quality of server OS going out the door was quite high, however it was hardly quick, never fully-automated, and “rush” requests were the only way developers could get an OS in a reasonable amount of time.
See the below graphic outlining each provisioning component. I’ve highlighted the areas of automation concern:
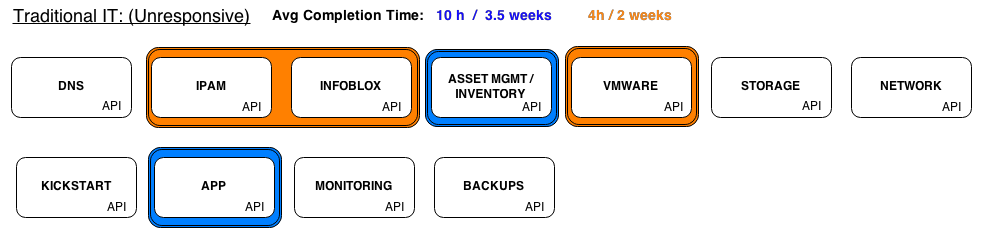
We spent a ton of time analyzing how we could improve this process. We eliminated steps where feasible, automated what we could, created efficiencies, etc. After much scrutiny and completing all the “low-hanging-fruit”, we realized we weren’t ever going to be able to get down to the 15-20 minutes timeframe that developers were expecting (and were getting from other sources such as Amazon). We realised our limiting factors were the very tools themselves that we were using in each component. If our IPAM tool didn’t have an available API, we would never be able to programmatically address (read automate) our IP requirements. Similarly, if we couldn’t programmatically tie into our asset management tool, we’d be forever stuck with manual tasks to enter the data. In order to automate the entire process of server provisioning, we were in a “rip and replace” situation on some of our core server provisioning components. Ouch. What a sobering realization. As you can expect, ripping and replacing components wasn’t a very popular idea with the business, as there were large investments in each component and they were very useful and functional to other areas of the business. What was IT to do?
Enter infrastructure-as-a-service (IaaS), and more specifically, OpenStack. OpenStack was designed with these infrastructure limitations in mind. All of the common components in the traditional IT provisioning workflow were implemented in OpenStack with a capable API. In fact, the API is the only way to interact with these components. No more being locked-in with a vendor’s short sighted roadmap. Also, being an open-source project, if the API capability wasn’t there that you expected, you could engage the community to include your feature, or develop it yourself.
Once we discovered IaaS, we were quickly looking at how we could get it in house, and fast. As we learned about OpenStack and private/public clouds, we started to see where this was going to work for us, and where it was not. We discovered that most of the rush systems the developers were looking for were for testing/developing new capabilities, and were tied to time-to-market activities or other time-sensitive new business constraints. Most of the business critical systems were still being satisfied by the traditional provisioning method. We decided to PoC OpenStack for this developer test bed use-case, and look at a workload promotion process to the traditional IT environment once the business decided these new capabilities were worth pursuing seriously. We’ve ended up with a provisioning architecture like this:
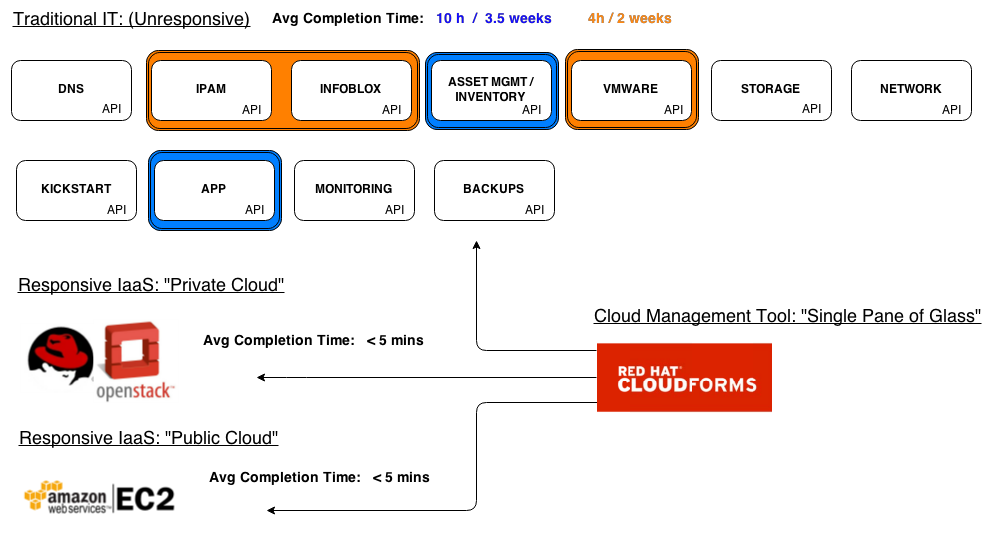
We realised the traditional IT provisioning method was going to be around for quite some time for legacy systems. We also realised that we did have some workloads that would suit an IaaS method, and that we still had developers going to Amazon for bleeding edge development we couldn’t bring in house just yet. This left us with three different methods of server provisioning, so we decided upon Red Hat’s cloud management tool to orchestrate each provisioning workflow. This will allow us to perform consistent policy and process enforcement, as well as automate similar tasks, across all provisioning workflows. While we’re still working on integrating several of the automation components of each workflow, we soon will have sufficient ways to automate server provisioning for use-cases that need quick responses, while still satisfying the traditional IT legacy use-cases that our business will be running for quite some time. This will leave us in a private hybrid cloud state, with the agility to scale up or down any provisioning workflow we need as our business needs evolve.